A.I to Open Interpreter to LLMs
Table of Contents
Open Interpreter
python -m venv myenv && source myenv/bin/activate && pip install open-interpreter
Running the interpreter:
interpreter
/home/atulyaraaj/Desktop/Projects/Python/Open Interpreter/myenv/lib64/python3.12/site-packages/pydantic/_internal/_config.py:345: UserWarning: Valid config keys have changed in V2:
* 'fields' has been removed
warnings.warn(message, UserWarning)
●
Welcome to Open Interpreter.
────────────────────────────────────────────────────────────────────────────────────────────────────
▌ OpenAI API key not found
To use gpt-4o (recommended) please provide an OpenAI API key.
To use another language model, run interpreter --local or consult the documentation at
docs.openinterpreter.com.
────────────────────────────────────────────────────────────────────────────────────────────────────
OpenAI API key:
Let’s go local
interpreter --local
Ollama
└─(06:16:53)──> interpreter --local ──(Fri,Jan24)─┘
/home/atulyaraaj/Desktop/Projects/Python/Open Interpreter/myenv/lib64/python3.12/site-packages/pydantic/_internal/_config.py:345: UserWarning: Valid config keys have changed in V2:
* 'fields' has been removed
warnings.warn(message, UserWarning)
Open Interpreter supports multiple local model providers.
[?] Select a provider:
> Ollama
Llamafile
LM Studio
Jan
Ollama is not installed or not recognized as a command.
Please visit https://ollama.com/ to download Ollama and try again.
Download Ollama:
curl -fsSL https://ollama.com/install.sh | sh
This will take some time.
You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models. From Ollama Github
Ollamma also installing »> NVIDIA GPU installed.
Downloading the model:
[?] Select a model:
> llama3
↓ Download llama3.1
↓ Download phi3
↓ Download mistral-nemo
↓ Download gemma2
↓ Download codestral
Browse Models ↗
I don’t which version of llama to go for lol.
I guess
Llama 3.1 8B 4.7GB ollama run llama3.1
Update: it’s 4.9GB now.
While it is downloadig let’s explore:
Model providers:
[?] Select a provider:
> Ollama
Llamafile
LM Studio
Jan
Ollama is one of these many model providers.
Jan:
Download for linux.
I am getting the .appimage file.
By the data I am getting from all these is:
There are :
- Propreitary AI providers and models
- Open AI
- Anthropic
- Open Source
- Ollama - Llama by Meta
- Phi by Microsoft
- Gemma by Google
- Mistral
So these open source models are competing with Propreitary models. In terms of accuracy and speed.
Loading llama3.1...
Model loaded.
▌ Model set to llama3.1
Open Interpreter will require approval before running code.
Use interpreter -y to bypass this.
Press CTRL-C to exit.
────────────────────────────────────────────────────────────────────────────────────────────────────
▌ We're training an open-source language model.
Want to contribute? Run interpreter --model i to use our free, hosted model. Conversations with this
i model will be used for training.
I guess llama3.1 has been loaded.
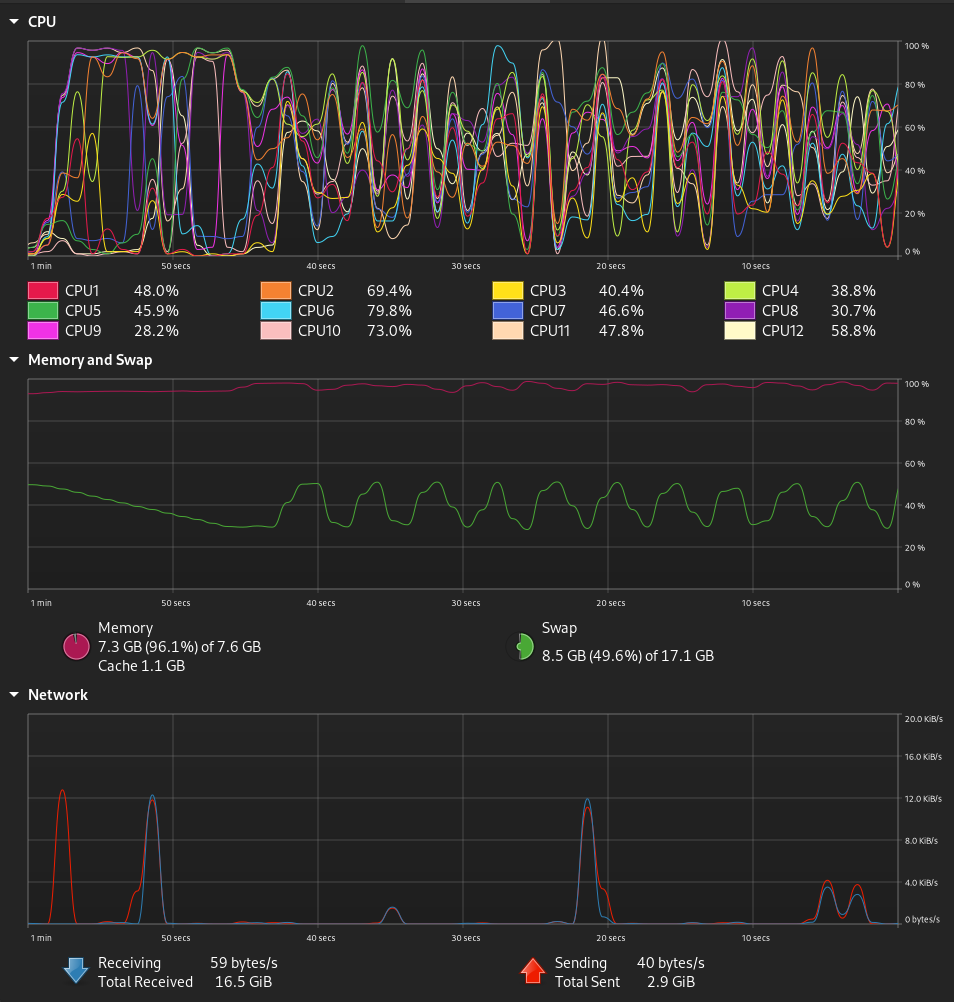
I just typed hello on this interpreter and got:
{"name": "execute", "arguments":{"language": "python", "code": "print('Hello')"}}
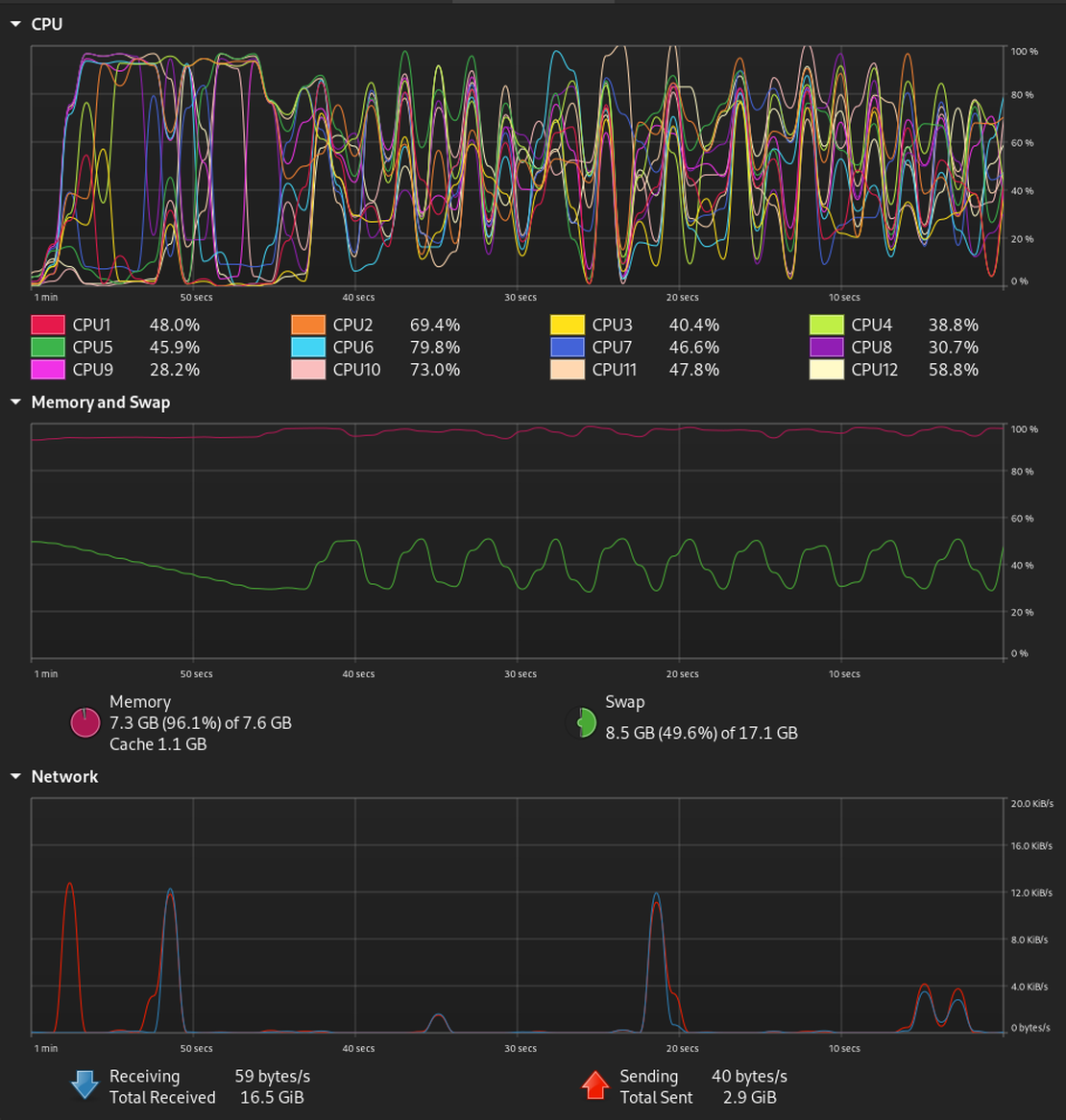
This is quite heavy on my system I feel. Another reason to get one.
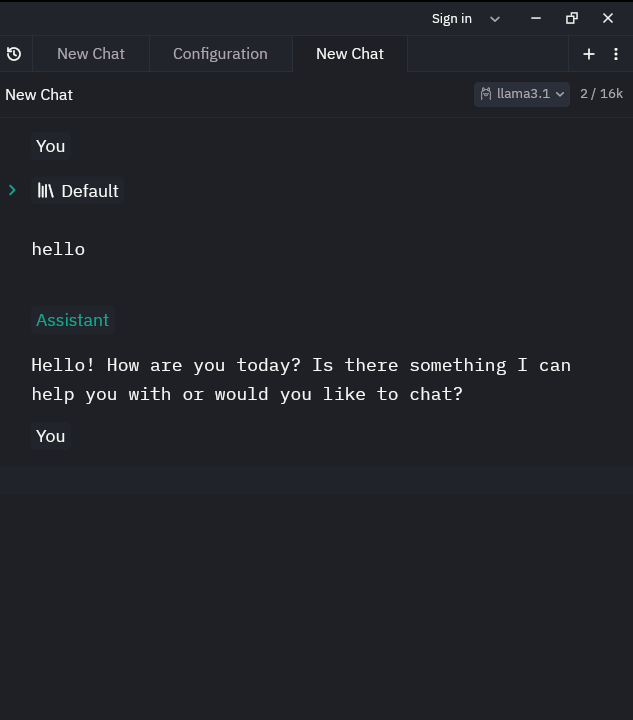
This is the output from Zed text editor. Wow! I was wondering how this works and see, now I am running my own local LLM model and interacting with it.
Cool!!
Ollama:
ollama run llama3.2
└─(06:57:26 on master ✭)──> ollama ──(Fri,Jan24)─┘
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
ollama
ollama stop
ollama list
ollama ps
ollama stop 46e0c10c039e
ollama stop llama3.1:latest
Phew!! My RAM is offloaded now.
While I was testing these feature I have downloaded Jan and LMstudio.
Let’s see what they has to offer.
LM Studio
It’s a good UI.
ollama run llama3.1:latest
Jan
Her UI is good too.
For now all I could do is look at the UI as I couldn’t figure out way to add my local Llama model.
Now I will turn on my GPU and see how Ollama performs.
Llama with GPU!!
With GPU I could get Llama3.1 to get all these text data. This is so cool.
Just wow.
As these models requires a lot of compute, the companies like OpenAI, Anthropics gave the general public their cloud provided LLMs.
So, from using Transformers from online to offline seems amazing. When things are online you are not somewhat certain, how the actual work is going on.
Now, the LLM is running inside my own computer, in OS for my choice, by Model provider of my choice and the open LLM itself. Wow, how much power does it gives you now.
Now you and your lil/big buddy can really take things to super next level.
I feel that way we used internet will change by a lot. Not will, is changing by very much a lot from using these AI agents.
We were just look for information then we started to store it, use it. The ways has changed drastically. From longer videos to short video consumptions. And, now, this?? A complete new way towards information. Awesome!